一个高速数据采集框架
24 Feb 2017数据采集系统必须能够正确处理数据源产生的所有数据,尤其是实时数据采集系统。 但是,数据的产生速度是远远快于处理过程的,那么如何获得更高的采集和处理性能就是数据采集系统最核心的问题。
简介
该框架主要用于一个基于Xilinx的ZYNQ平台的自动化测试系统,该系统通过FPGA控制ADC/DAC采集原始数据,然后经由CPU简单处理后上传服务器。 在该系统中FPGA采集数据具有高速,突发的特点,因此CPU必须能够及时的响应并快速处理原始数据,保证采集数据的完整性。
下图简单描述了一个数据采集系统如何从硬件采集原始数据并传输给数据处理系统的过程。
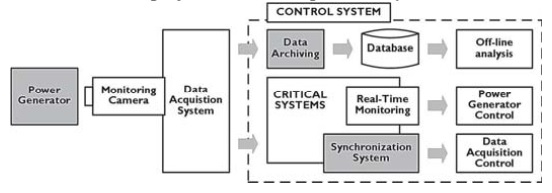
相关问题及工作
在描述这个框架怎么实现之前,我们先来说明实现这样一个框架遇到的问题以及解决方法。
FPGA与CPU之间的数据传输
在传统的MCU和FPGA的架构中,FPGA与MCU的高速数据传输是一个很大的挑战。 Xilinx的ZYNQ系列产品提供了一个用于CPU与FPGA之间传输高速数据的总线,在此基础上,通过DMA方式,数据处理线程可以通过内存访问的方式直接处理FPGA采集的原始数据。
锁
如何让慢速的数据处理不影响高速数据采集,那么数据处理采用并发方式是必然选择,即单线程数据采集,多线程数据处理。 在并发中,锁是解决竞争问题最简单的方法,但是锁也是慢的。
内核态的锁需要操作系统进行一次上下文切换,等待锁的线程会被挂起。而在上下文切换的时候,CPU之前缓存的指令和数据都将失效,对性能有很大的损失。用户态的锁虽然避免了这些问题,但是其实它们只是在没有真实的竞争时才有效。
Disruptor(LMAX公司开源的一个高效的内存无锁队列)团队技术博客文章《Dissecting the Disruptor: Why it’s so fast (part one) – Locks Are Bad》详细的说明了锁为什么是慢的,这里是中文翻译。 简单的说就是竞争导致速度慢,没有竞争速度就快,那么如何没有竞争呢?
无锁队列
Disruptor实现了一个高效的内存无锁队列,在单生产者,多消费者的情景下,Disruptor做到了真正的无锁队列。 数据采集系统是一个标准的单生产者,多消费者的情景,原始数据的采集线程作为生产者,数据处理线程作为消费者,为了提高处理速度使用多个数据处理线程。
因此该框架的核心是一个参考Disruptor实现的只适用于单生产者,多消费者情景的真无锁队列。 酷壳上的《并发框架Disruptor译文》列举了一系列文章,对理解和使用Disruptor大有帮助。
线程相关性
POSIX调度接口提供了一种通过建立CPU关联掩码把线程绑定到指定CPU执行的机制,这样可以降低线程之间的干扰。 在框架中,把数据采集线程和处理线程分开,数据采集线程单独指定CPU执行,这样可以防止处理线程占用过多CPU导致采集线程不能处理数据突发的问题。在CPU核数足够的情况下,处理线程也可以指定CPU执行,这样进一步提升数据处理能力。
后续改进
目前采集速度可以达到3Gb/s,接下来最大的任务是进一步提升数据处理速度。 在无锁队列的基础上,数据处理可以进行进一步的划分,实现流水线形式数据处理,进一步提升性能。